Künstliche Intelligenz verändert grundlegend, wie wir Informationen aus der großen Menge an Daten im Internet herausfiltern. Ein spannendes Werkzeug dabei sind KI-Crawler – intelligente Systeme, die Webseiten durchsuchen, relevante Daten sammeln und Muster erkennen können. ChatGPT-4 ist ein Beispiel einer solchen leistungsstarken Technologie. Diese Technologien bieten zwar zahlreiche Vorteile, bringen jedoch auch Einschränkungen mit sich. Der Einsatz von KI-Crawlern kann die Performance deiner Website erheblich beeinträchtigen und wirft zudem wesentliche ethische Fragen auf, insbesondere hinsichtlich des Schutzes geistigen Eigentums sowie der Sicherheit persönlicher Informationen und Daten. Es ist daher wichtig, sich stets zu überlegen, welche Daten mit KI-Crawlern geteilt werden können und welche besser vor unbefugtem Zugriff geschützt bleiben sollten. Diese Herausforderungen erfordern sorgfältige Überlegungen und eine bedachte Herangehensweise.
In diesem Blogbeitrag erläutern wir die Funktionsweise von KI-Crawlern näher und zeigen dir, wie du deine Website davor schützen kannst, dass deine Daten unerwünscht verarbeitet werden.
Was sind KI-Crawler?
KI-Crawler sind fortschrittliche Software-Systeme, die das Internet durchsuchen, um Informationen zu finden und zu speichern. Sie nutzen künstliche Intelligenz, um Muster zu erkennen und Kontexte zu verarbeiten. Diese Eigenschaften machen Crawler besonders nützlich für Suchmaschinen, Datenanalysen und digitale Marketingstrategien.
Diese Technologie ermöglicht es KI-Crawlern, große Mengen an Webinhalten zu verarbeiten und intelligente Entscheidungen über den Wert und die Relevanz der gesammelten Informationen zu treffen. Sie sind somit ein wichtiger Bestandteil der modernen Informationsgesellschaft, da sie zur Strukturierung und Zugänglichkeit von Daten beitragen.
Wie funktionieren KI-Crawler?
Um die Funktion des KI-Crawlers besser zu verstehen, zeigt das Schaubild, wie eine KI funktioniert und an welchem Punkt der KI-Crawler greift.
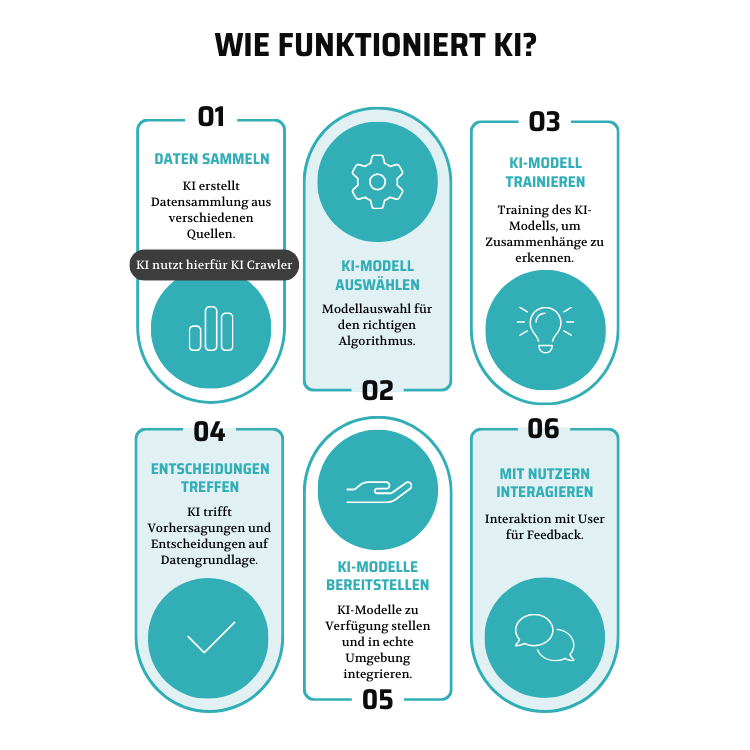
KI-Crawler beginnen ihren Prozess mit einer Liste von Start-URLs, den sogenannten Seeds. Diese URLs stammen von bekannten Websites, Verzeichnissen oder werden durch Links gefunden, die auf den bereits besuchten Seiten zu sehen sind. Sie folgen den Links auf diesen Seiten, analysieren den Inhalt und speichern relevante Informationen in einer Datenbank. Diese Daten werden von Suchmaschinen verwendet, um auf Anfragen zu reagieren.
Moderne KI-Crawler sind in der Lage, verschiedene Medienformate wie Text, Bilder und Videos zu erkennen. Sie verwenden maschinelles Lernen, um den Kontext und die Bedeutung der Inhalte zu verstehen, was präzisere Suchergebnisse ermöglicht. Diese Fähigkeit verbessert nicht nur die Suchergebnisse in Suchmaschinen, sondern hilft auch künstlichen Intelligenzen wie Chatbots und Sprachassistenten, genauere und kontextuell passende Antworten zu liefern.
Unterscheidung zwischen KI-Crawler und Webcrawler
Neben herkömmlichen Webcrawlern, die Webseiten durchsuchen und Inhalte für Suchmaschinen speichern, gibt es auch KI-Crawler. Diese sind weiterentwickelt und können komplexe Muster erkennen sowie kontextbezogene Daten erfassen.
| KI-Crawler | Webcrawler | |
|---|---|---|
| Definition | Webcrawler mit künstlicher Intelligenz und maschinellem Lernen | Allgemeine Webcrawler, die das Web durchsuchen und Inhalte speichern |
| Technologie | KI-Algorithmen | Einfache Algorithmen |
| Medienformate | Erkennen Texte, Bilder und Videos | Fokus auf Texte |
| Interaktivität | Interagieren mit dynamischen Inhalten wie z.B. Buttons auf Websites | Folgen strikt den vorgegebenen Anweisungen und sind weniger flexibel |
| Anwendungen | Suchmaschinen, Chatbots, Assistenten | Hauptsächlich Suchmaschinen, Preisvergleiche und Datenanalyse |
| Datenverarbeitung | Komplexes Analysieren und Interpretieren der Daten | Einfaches Sammeln und Speichern von Daten |
Wenn du tiefer in das Thema Crawlability und Indexierung eintauchen möchtest, lohnt sich ein Blick in den Blogbeitrag „Crawlability: Tipps & Tricks“ von Daniel Herrmann. Dort erfährst du, wie entscheidend eine gute Crawlability für den Erfolg deiner Suchmaschinenoptimierung ist.
Vorteile von KI-Crawler?
Webinhalte vor KI-Crawlern schützen
Wenn KI-Crawler Daten umfassend analysieren, können Inhalte von Websites in Datenbanken erfasst werden. Während dies offensichtliche Vorteile bietet, entstehen dadurch aber auch Bedenken hinsichtlich des Schutzes der eigenen Daten.
Um solche Bedenken zu senken, können Betreiber einer Website eine simple robots.txt-Datei verwenden. Mit dieser Datei geben die Betreiber der Website den KI- bzw. Suchmaschinen-Crawlern Anweisungen dazu, welche Bereiche durchsucht werden dürfen und welche nicht. Was nicht automatisch bedeutet, dass sich alle KI-Crawler an diese Anweisungen halten. Zudem bedeutet das für die Website, dass die Crawler immer noch eine erhebliche Performance-Beeinträchtigung durch künstlich erzeugten Traffic bewirken.
Um die KI-Crawler gänzlich vom Crawlen der Website auszuschließen, braucht es zusätzlichen Schutz. Hierbei ist der Einsatz eine Web Application Firewall (WAF) wie z.B. Cloudflare unerlässlich. Cloudflare hilft den Einsatz von KI-Crawlern zu kontrollieren und gleichzeitig die Performance zu verbessern. Besonders wichtig sind dabei Funktionen wie Traffic- und Bot-Management, DDoS-Schutz, Caching und SSL/TLS-Verschlüsselung. Diese Maßnahmen tragen wesentlich dazu bei, die Privatsphäre der Nutzer zu wahren und sicherzustellen, dass die Inhalte der Website nur gemäß den Vorstellungen des Betreibers genutzt werden.
Das könnte dich auch interessieren
-
GEO-Monitoring: Herausforderungen im Vergleich zu klassischem SEO-Monitoring
GEO-Monitoring ist deutlich schwerer messbar als klassisches SEO Monitoring, weil KI-Suchen andere Signale liefern und viele Entscheidungen direkt in der Antwortoberfläche ohne Klick auf deine Website fallen. GEO ergänzt dein bestehendes SEO-Monitoring um neue Kennzahlen wie KI-Erwähnungen und Citations in KI-Antworten und zeigt dir, wo du bereits sichtbar bist – auch wenn sich das (noch) nicht eins zu eins im organischen Traffic widerspiegelt.
-
Sichtbar in der KI-Suche: So ergänzt GEO deine SEO-Strategie
Die Art, wie Menschen online nach Lösungen suchen, ändert sich rasant. Immer mehr Nutzer stellen ihre Fragen direkt an KI-Systeme wie ChatGPT, Perplexity oder Sprachassistenten. Für Unternehmen heißt das: Die klassischen SEO-Regeln reichen nicht mehr aus. Erfahre daher, wie du dein Unternehmen in KI-Suchen gezielt positionierst und auch dort gefunden wirst.
-
LLM Server Hosting: Private Cloud vs. öffentliche Cloud-APIs
Unternehmen holen LLMs aus dem Experimentierlabor in den produktiven Alltag. Der Beitrag zeigt, wie LLM Server Hosting funktioniert – und ob für dich private LLM-Server in der Private Cloud oder öffentliche LLM-APIs die bessere Wahl sind.



